World models have demonstrated superiority in autonomous driving, particularly in the generation of multi-view driving videos.
However, significant challenges still exist in generating customized driving videos. In this paper, we propose DriveDreamer-2,
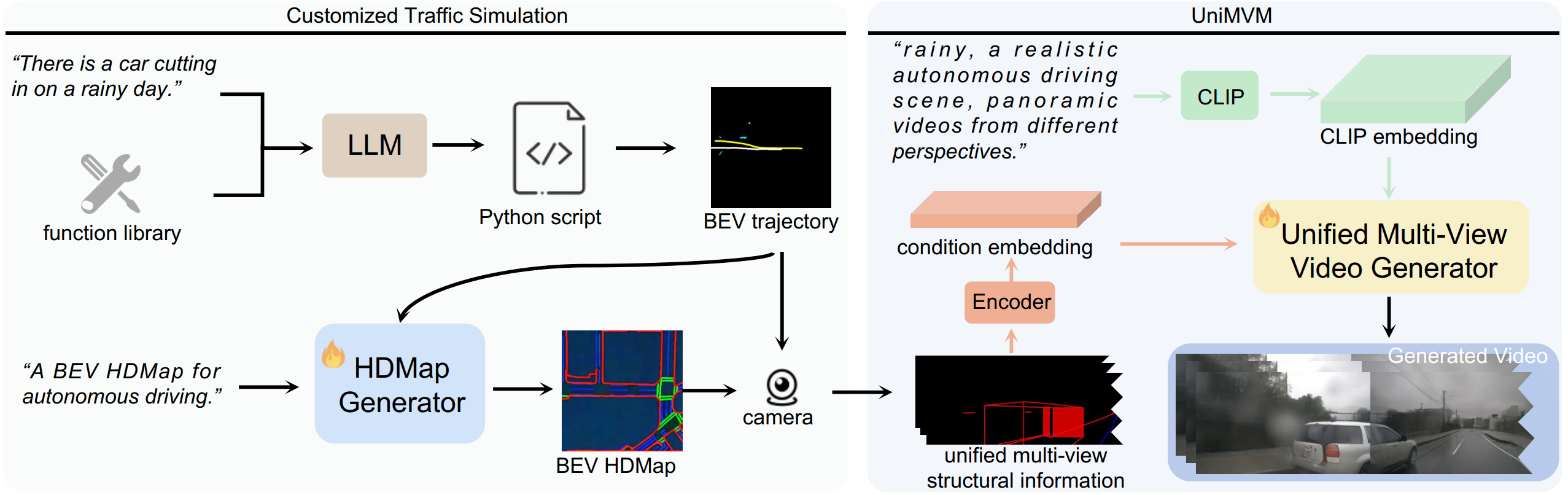
which builds upon the framework of DriveDreamer and incorporates a Large Language Model (LLM) to generate user-defined driving videos.
Specifically, an LLM interface is initially incorporated to convert a user's query into agent trajectories. Subsequently, a HDMap,
adhering to traffic regulations, is generated based on the trajectories. Ultimately, we propose the Unified Multi-View Model to enhance
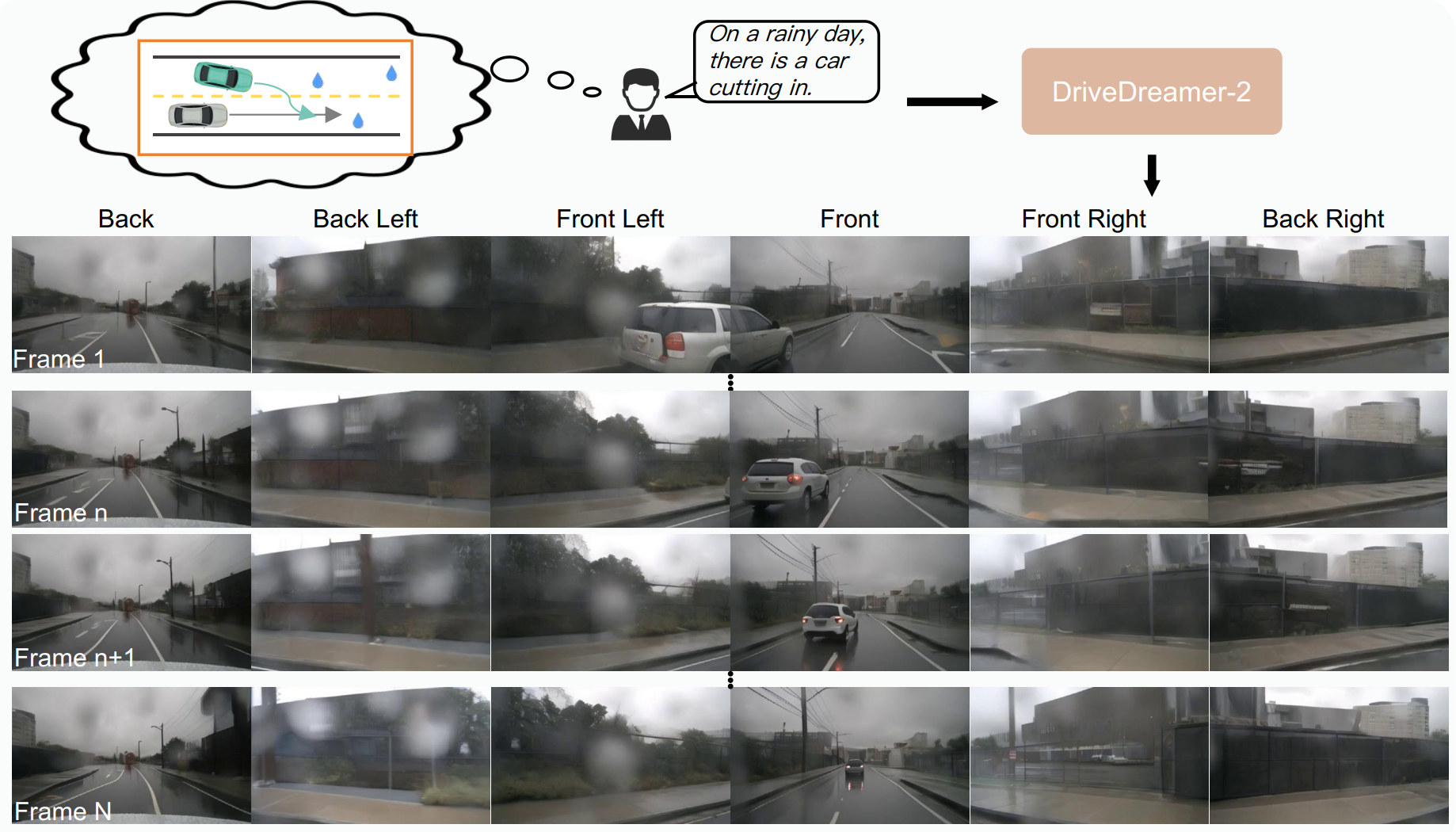
temporal and spatial coherence in the generated driving videos. DriveDreamer-2 is the first world model to generate customized driving videos,
it can generate uncommon driving videos (e.g., vehicles abruptly cut in) in a user-friendly manner. Besides, experimental results demonstrate
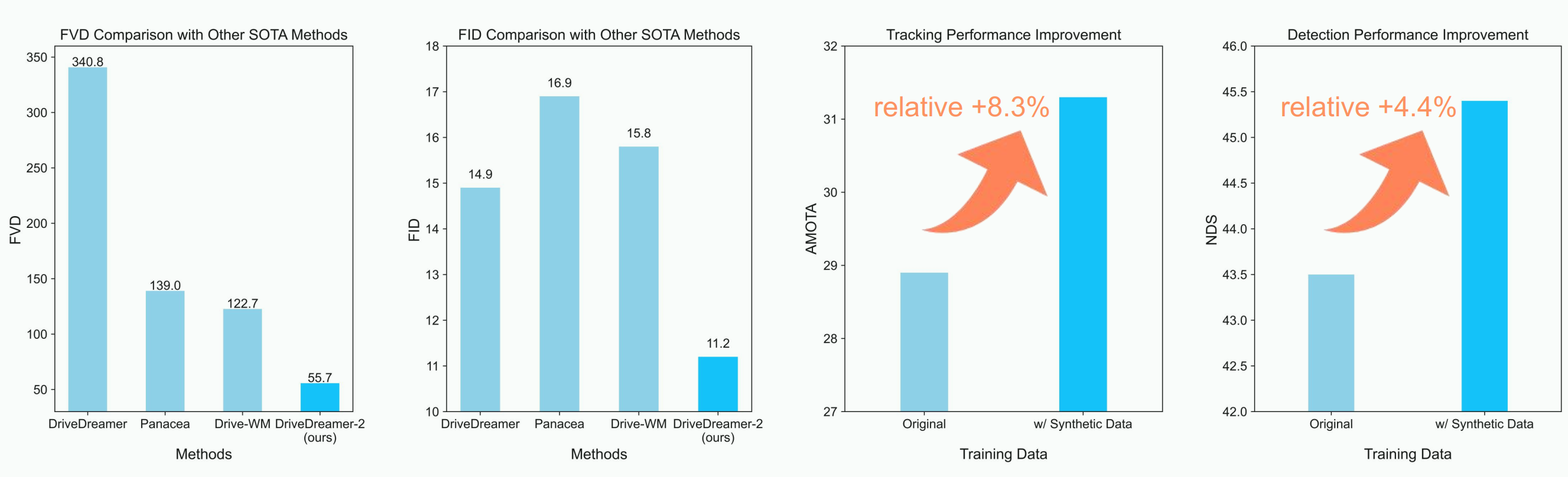
that the generated videos enhance the training of driving perception methods (e.g., 3D detection and tracking). Furthermore, video generation
quality of DriveDreamer-2 surpasses other state-of-the-art methods, showcasing FID and FVD scores of 11.2 and 55.7, representing relative improvements of 30% and 50%.